What are SCD's and why do they matter the most !
Naveen is currently a graduate student at University of Lethbridge pursuing his Thesis based masters degree.
Currently he is working as a Data Engineer Intern at Kastech Canada.
Previously he used to work for ValueMomentum as a Data Engineer.
Hello readers, this is naveen back again with a new topic on SCD's. As usual please read slowly and understand everything without losing anything...
So here is our Todays Story:
In this world of overarching data explosion, when you don't care about what's happening in your data repositories, it means that you are losing a golden chance, just because you don't the importance of it.

To illustrate the scenario succinctly, by the time you read this entire article, on hashnode my fellow bloggers might have published at least 5 articles (guess), or I might have got a read count increase on one of my articles, due to one of my LinkedIn post. Therefore if you are not making fast decisions out of the data you capture, then you might fall into a serious problem, where you might be stuck as everyone advances due to their better decision-making skills.
So conclusively, we can term this particular concept of decision making as business intelligence in a business domain, and in life, it could help you evaluate the next step, of what we are going to do.
Perfect Situation

Furthermore, In data analytics, our primary goal is to make decisions out of the data that we capture. So we need to have some standards for capturing the sporadic data in order to make meaningful decisions out of it. That's where we use SCD's to aid us in Business Intelligence.
SCD's are the techniques, that help us track the historic data in a dimension table, with the passage of time.
Example: Let us take, a scenario of the Users on hashnode, who were registered, and hypothetically let us assume Hashnode Data Architects are maintaining the DIM_USERS table. Where it contains all the users' names and the location history collected while filling the profile form as shown below.
Image Source: https://hashnode.com/settings
Assume this is the user's table.
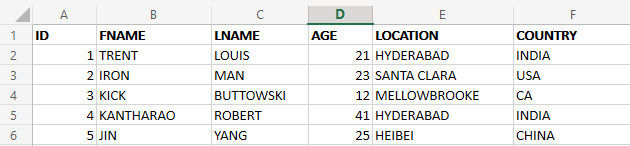
Now after few days sporadically, w.r.t to time assume the person has changed the location. Now let us see how different SCD's help us in tracking the data.
1) SCD 1 (Slowly Changing Dimension-1) : SCD1 is also called in-place update technique where the data is overwritten in place, without maintaining any history.
Example : Consider the below data, where we sample 5 users on Hashnode, with a default indicator value as N, so on day-x assume we have a new record with an exact match of id but with updated values then the following happens in SCD1.
DAY-1 records:

DAY-X record:

After performing the update operation, the data will look as below. Final records:

When you use SCD1 at places where we need to capture the historic records, then the data analyst honest feeling :

2) SCD 2 (Slowly Changing Dimesion-2 ) : So, In SCD2 we add a new row, which has an equivalency with the match keys, on the existing data, by adding an extra indicator and date columns to track the history of the Existing records .
Example: Let me take the previous data where we were having 5 records, so now we shall apply SCD-2 and will see what happens to the resulting data.
DAY-1 records:
Day-X record:

Final records

3) SCD 3 (Slowly Changing Dimension-3) : In SCD3, we add a new column, for every changed value in the table. which becomes hard to track when every column in the table changes, but in real-time this pattern is rarely used.
Question: As shown in the data what happens if we have another update on the row Kantha Rao as if he has moved from " New Zea land ---> Australia" ?
a) Do we need to add another column as country_3 and location_3 ! or what do you think is the alternative for that scenario?
Example:
DAY-1 Records:

Day-X Record:
Final Data:

Conclusion: So finally, when you choose to implement any particular pattern in your next project please have a perfect requirements analysis first, and then later you could choose one among the above.
Until then, if you really enjoyed my content please make sure you press the like button as it will motivate me to write such useful articles more and more frequently.
Just Follow it: Time is a precious commodity use wisely !

This is naveen signing off until then.



