

Photo by Kelly Sikkema on Unsplash
Snowflake Data Migration - Part 2
Snowflake Data Migration N Optimization


Hello Folks, Today I am back With another article On Snowflake, Data ingestion. And How to handle Data Engineering on Snowflake.
** Todays Agenda **
I will walk you through a sample architectural pattern, which ingests the data.
And will give few pointers on what to select, how to select a specific warehouse, inorder to optimize the data ingestion cost.
** 1) Sample Data Pipeline: **
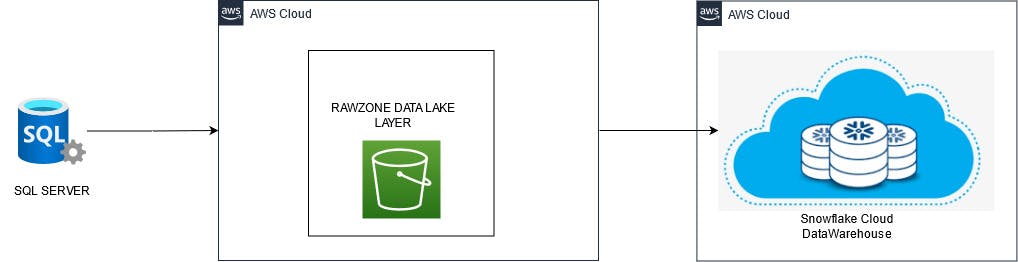
As you all know, In the first part i have discussed, the need of data lake and its usefulness in any Analytics Project. (Adding Link Over Here)
** Incremental Data Load: **
Firstly We integrate the data from different sources and will load them, into AWS S3 in a raw zone which acts as a datalake.
Because over S3 we store the data from multiple tables. As a Simple CSV Files ....
And Once the Load is Done We transfer the data from the Raw files into Snowflake Landing Layer, Using the
COPY INTOCommand.From there, we Perform a
Change Data Captureover main table fromCleaned Layerwhich will let us know whether the data arrived is Updated / Inserted so we respectively perform the necessary operations on the main table.Finally, once the data ingestion is completed we start building the data warehouse, i.e Dimensions and Fact Tables, to serve our business purpose. Which is usually Datawarehouse layer.
And at the end once the DW layer is Succesfully Completed, we clone them into semantic layer for visualization.
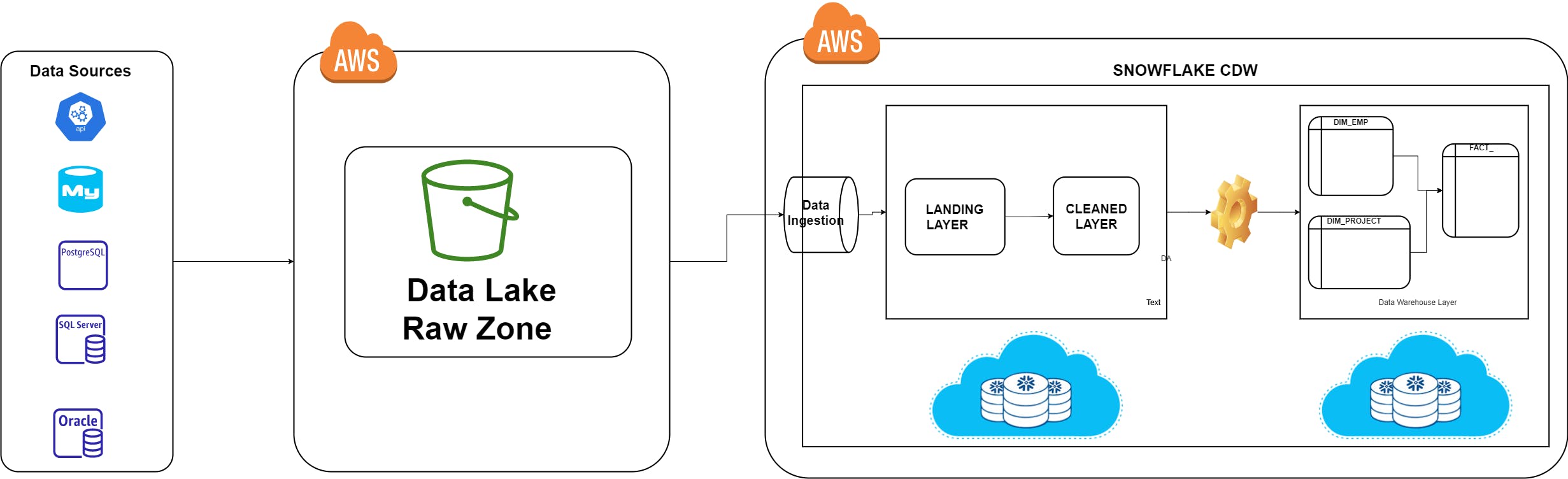
Data lake, is a storage layer where we store the data, from the source system as a raw file. But instead we will pad the dates and batch_id, for better debugging, and it also helps us avoiding data swamp.
** 2) How to Select a Specific Warehouse Based On File Size : **
** A) Data Ingestion: **
a) Lets assume our data is so small i.e MB's X-Small Warehouse is more than enough, to handle those kind of workloads.
b) Therefore, as the data size increases (i.e GBs) then choosing a Medium Warehouse Would be a good option, as according to the documentaion snowflake always suggests to load the data in multiple partitioned files, as the performance of data ingestion increases.

** B) Ingestion is Fine But What About Workload on Warehouse ? **
I often, hear many people saying these queries are damn computation intensive and they are taking huge time, Naveen What Should i do ?
So as per the performance optimization, snowflake suggests us to check via following Query.
--LIST OF WAREHOUSES AND DAYS WHERE MCW COULD HAVE HELPED
SELECT TO_DATE(START_TIME) as DATE
,WAREHOUSE_NAME
,SUM(AVG_RUNNING) AS SUM_RUNNING
,SUM(AVG_QUEUED_LOAD) AS SUM_QUEUED
FROM "SNOWFLAKE"."ACCOUNT_USAGE"."WAREHOUSE_LOAD_HISTORY"
WHERE TO_DATE(START_TIME) >= DATEADD(month,-1,CURRENT_TIMESTAMP())
GROUP BY 1,2
HAVING SUM(AVG_QUEUED_LOAD) >0
;
Code Snippet Taken from Snowflake Quickstarts
If the Column, SUM_QUEUED values are greater than zero it means, for those queries using MCW (Multi Cluster Warehouse), is Highly recommended.
This is also called Scaling in/out.
** C) Hmm, Then When to Scale Up ? **
Ok, Fine there is a solution, For this problem too So, if you ever see a spillage over the network While the query is Executing
Looks Something Like this (We Will Have Network Spillage Row too )
At that time Scaling Up would be beneficial !
--LIST OF WAREHOUSES AND QUERIES WHERE A LARGER WAREHOUSE WOULD HAVE HELPED WITH REMOTE SPILLING
SELECT QUERY_ID
,USER_NAME
,WAREHOUSE_NAME
,WAREHOUSE_SIZE
,BYTES_SCANNED
,BYTES_SPILLED_TO_REMOTE_STORAGE
,BYTES_SPILLED_TO_REMOTE_STORAGE / BYTES_SCANNED AS SPILLING_READ_RATIO
FROM "SNOWFLAKE"."ACCOUNT_USAGE"."QUERY_HISTORY"
WHERE BYTES_SPILLED_TO_REMOTE_STORAGE > BYTES_SCANNED * 5 -- Each byte read was spilled 5x on average
ORDER BY SPILLING_READ_RATIO DESC
;
Code Snippet Taken from Snowflake Quickstarts
**Summary : **
Few Take Aways
Sample Data Ingestion Pipeline.
Best Practises: Always Select a Minimal Warehouse For Data Ingestion because using a large one doesnt help u in anyway.
And make, sure that Files Ingested, are as per the warehouse capacity.
Finally, Choosing When to Go With MCW (Multi Cluster Warehouse) and Scale Up/ Scale Down Option .
I really thank everyone, out there who has spared some time in reading the above article. I hope it helps people out there who are working on snowflake to optimize their workloads. Until then, take care and press the like button if you have learned something from the above content.